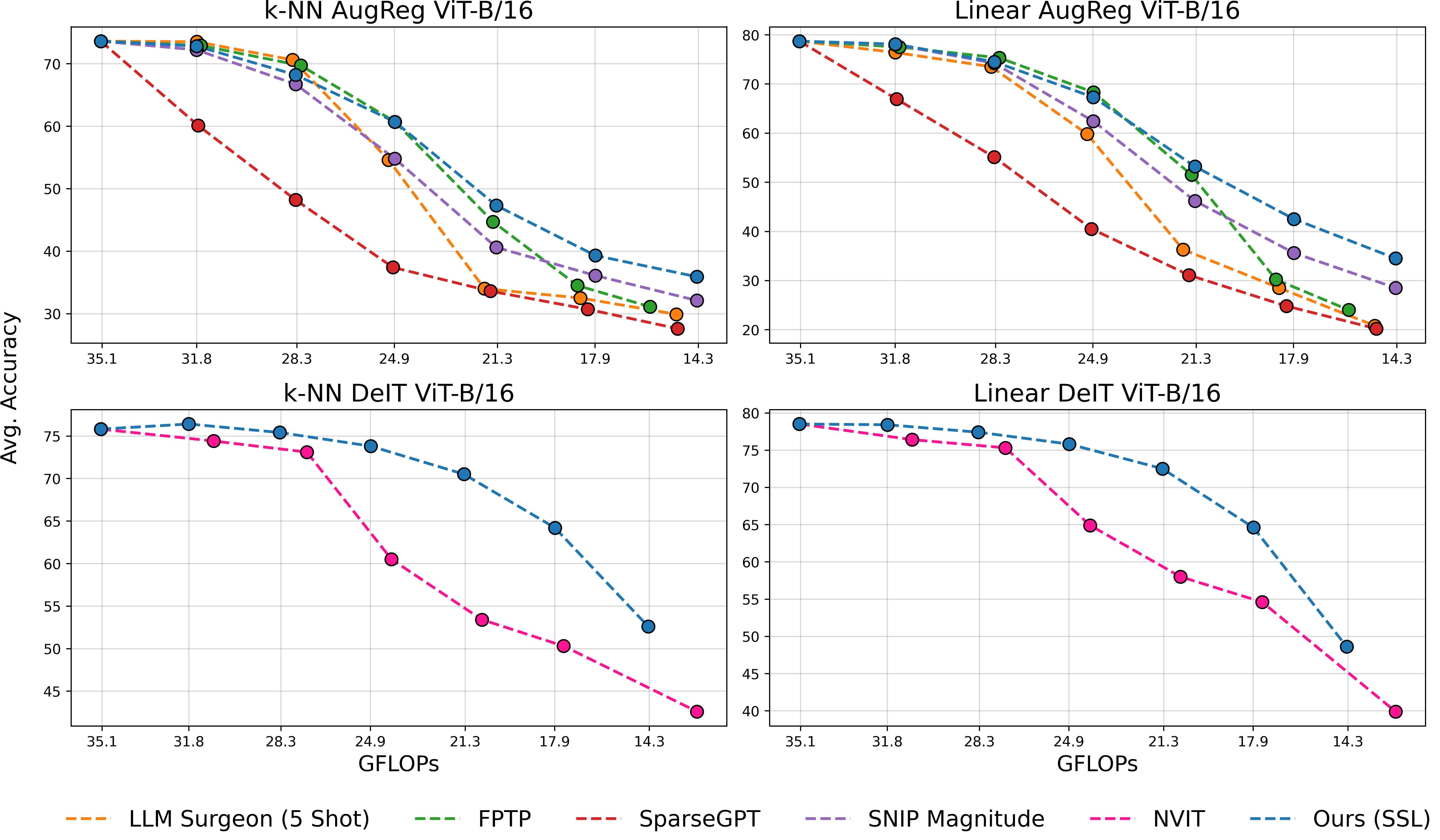
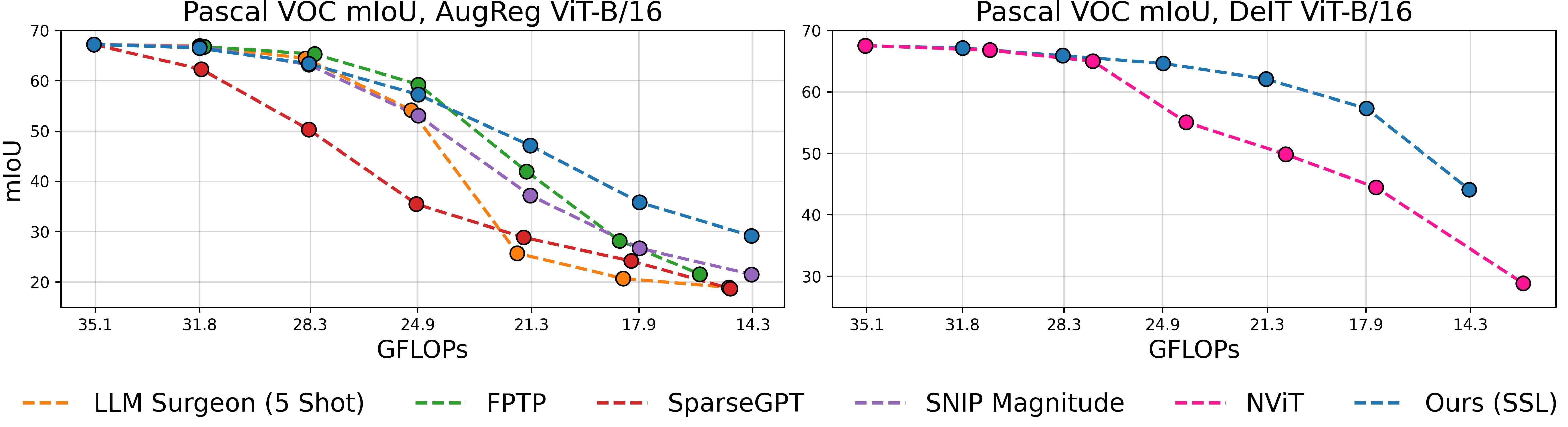
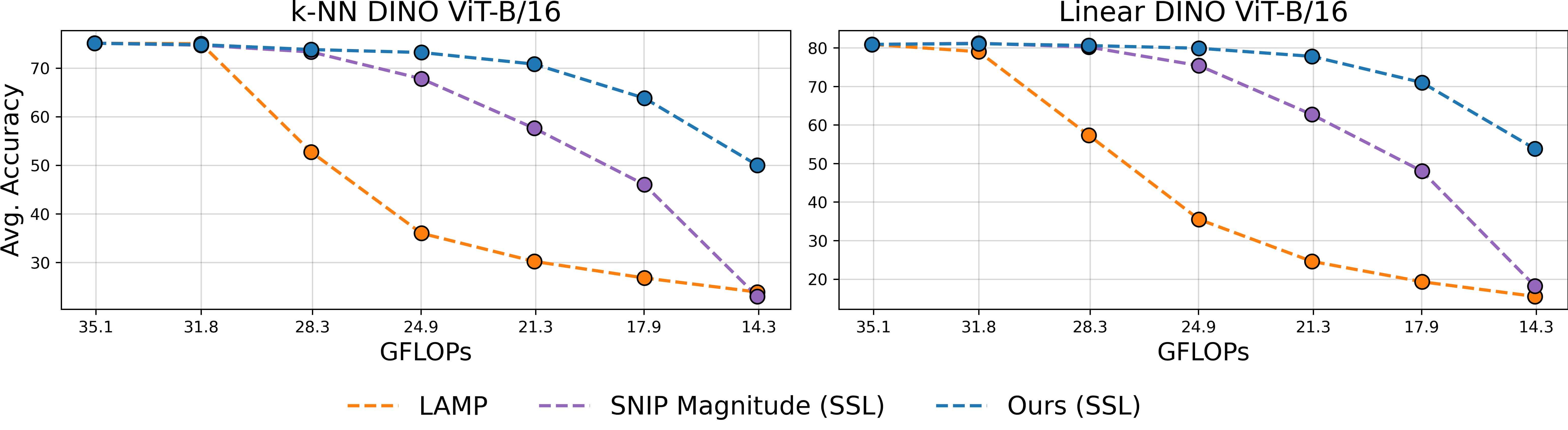
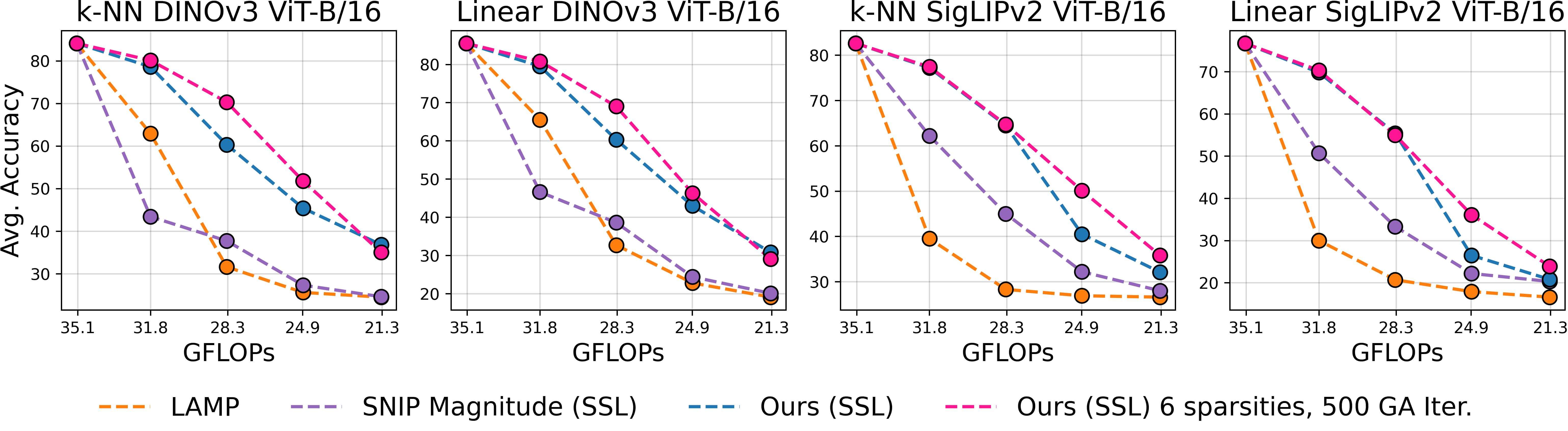
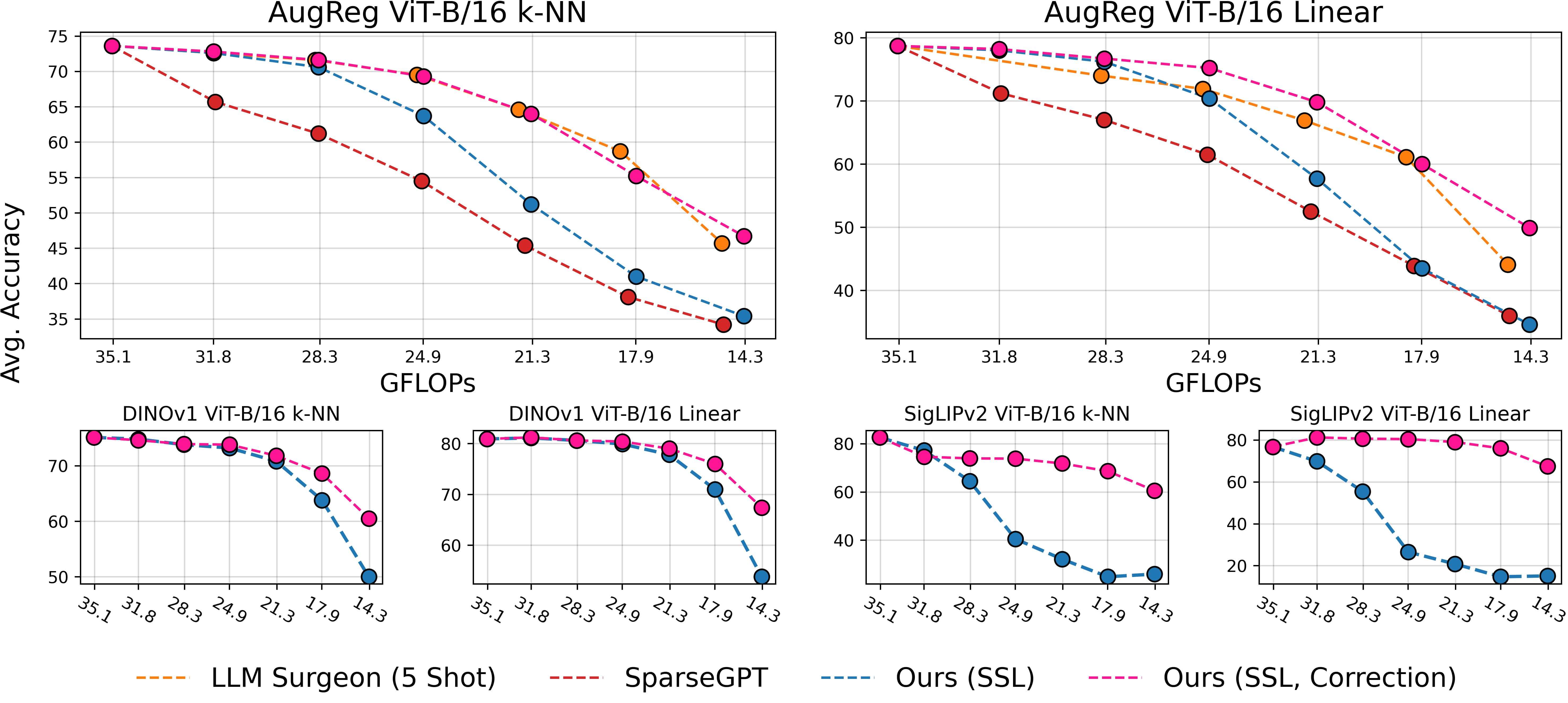
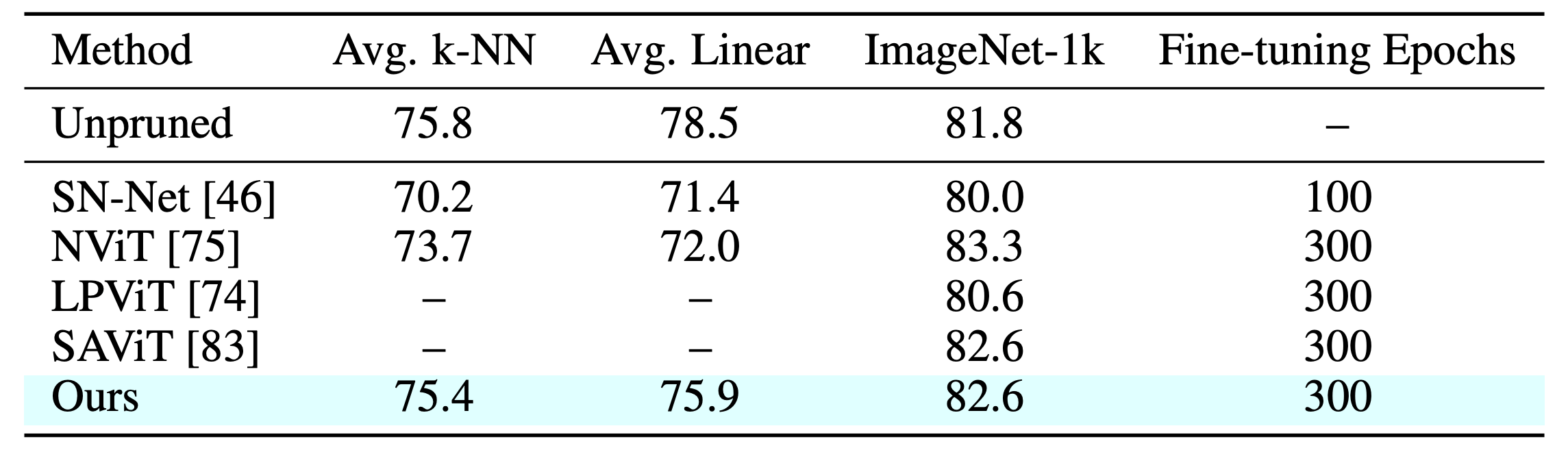
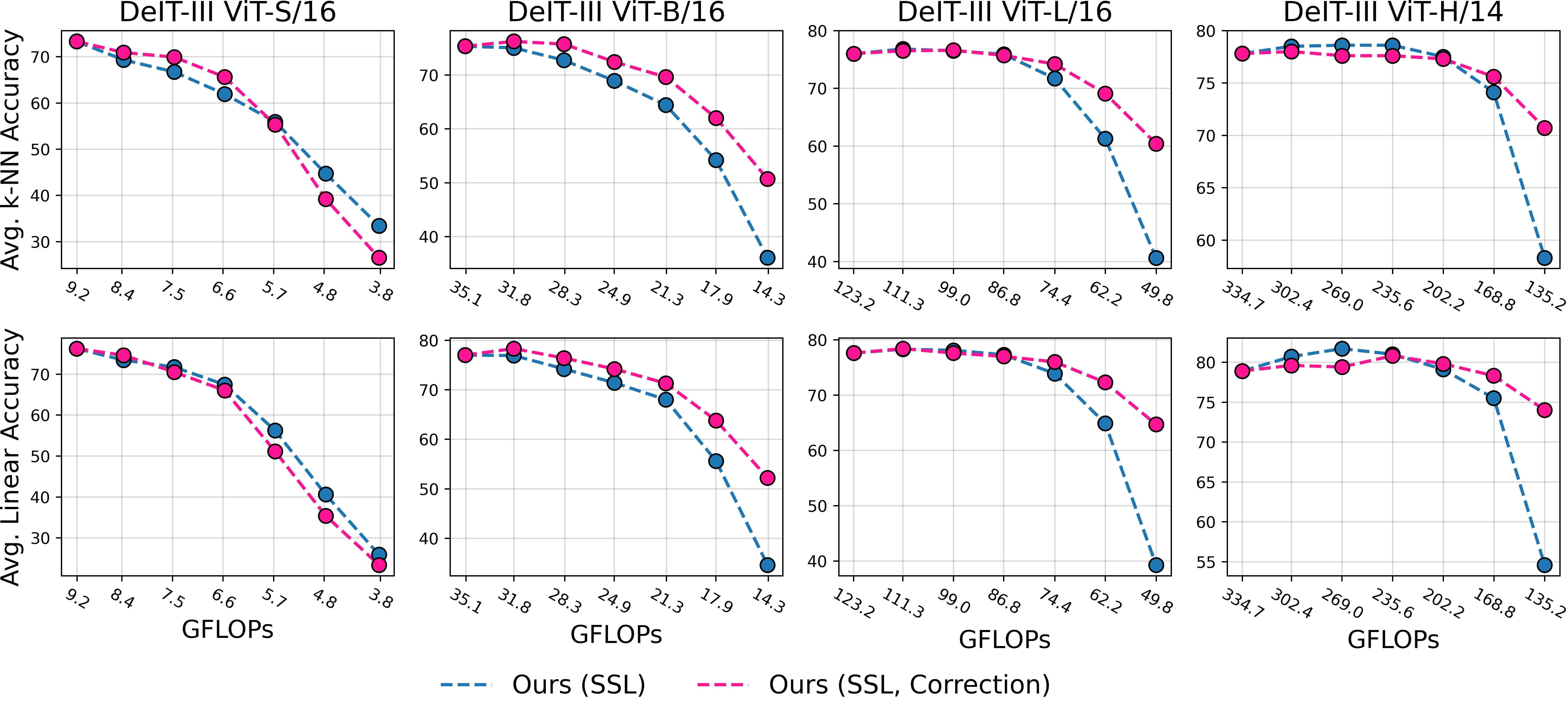
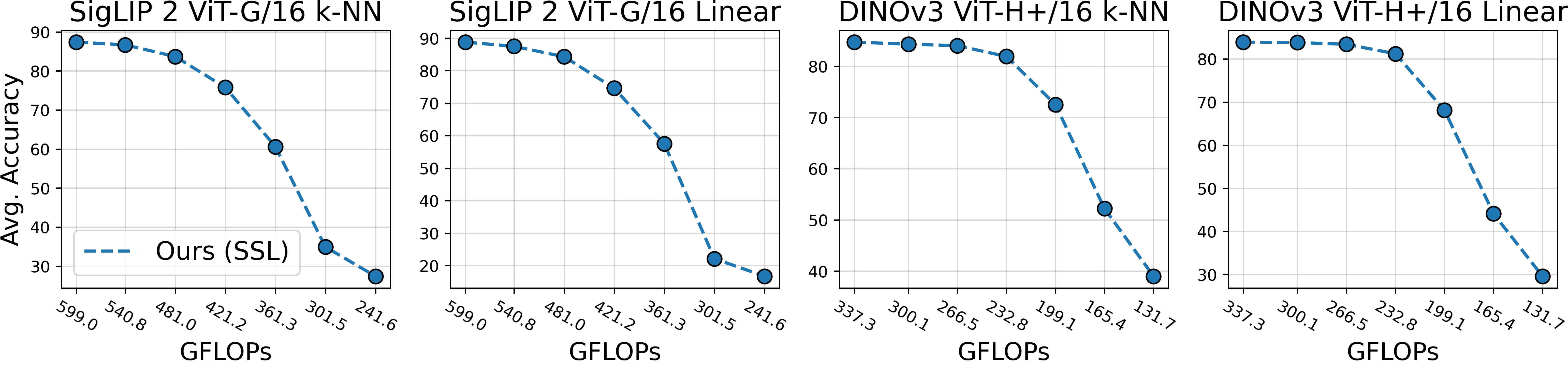
Figure 1: Overview of our method. We make pretrained models elastic in four steps: 1️⃣ we estimate the local inter-layer curvature via self-supervised gradients, 2️⃣ we model cross-network structure interactions via an evolutionary algorithm, 3️⃣ we fuse local and global scores in a unified importance measure, and 4️⃣ we rank structures once to derive subnetworks for any arbitrary sparsity.
This section briefly illustrates the key ideas behind our method. For more details, please refer to the paper.
The importance of a parameter can be expressed by the change it induces in the objective function \( \mathcal{L} \) when perturbed or removed. Following common practice, we approximate the loss variation under a small perturbation \( \delta\boldsymbol{\theta} \) as:
\[
\begin{align}
\delta \mathcal{L}
&=
\nabla_{\boldsymbol{\theta}}\mathcal{L}^{\top}\delta\boldsymbol{\theta}
+ \tfrac{1}{2}\delta\boldsymbol{\theta}^{\top}\mathbf{H}\delta\boldsymbol{\theta}
+ \mathcal{O}(\|\delta\boldsymbol{\theta}\|^3).
\end{align}
\]
Assuming the model is near a local minima, the gradient term \( \nabla_{\boldsymbol{\theta}}\mathcal{L}^{\top}\delta\boldsymbol{\theta}\!\approx\!0 \) vanishes, and the Hessian \( H \) remains the dominant sensitivity indicator. Computing the whole Hessian is intractable as it scales quadratically with the number of parameters. Thus, we approximate it via a local term \( H^{(l)} \), i.e., the Hessian diagonal, capturing intra-block sensitivities and a global term \( H^{(g)} \), which models the off-diagonal interactions between functional structures such as transformer blocks and attention heads, via an evolutionary algorithm. We first 1️⃣ estimate the local curvature as:
\[
\boldsymbol{H}^{(l)}
\approx
\frac{1}{N_D} \sum_{i=1}^{N_D}
\left\| \nabla_{\boldsymbol{\theta}} \mathcal{L}_i \right\|^2.
\]
To obtain gradients in a model-agnostic way, we adopt the self-supervised DINO objective, removing the dependency on a classification head, and allowing the pruning of both supervised and self-supervised models. We then 2️⃣ estimate cross-network interactions via the Exponential Natural Evolution Strategy (xNES) by simulating pruning and measuring sensitivity directly. To do so, we sample individuals \( \mathbf{c}\!\sim\!\mathcal{N}(\boldsymbol{\mu},\boldsymbol{\Sigma}) \) which represent structure-wise reweightings. For each individual, we rescale the local sensitivity scores, compute pruning masks, prune and measure the divergence in cosine similarity between features from the original and pruned models. The genetic algorithm optimization evolves \( \Sigma \) towards the inverse of the true cross-structure Hessian. While this is an approximation, in practice the off-diagonal terms of \( \Sigma \) evolve to mirror cross-structure dependencies and form a tractable approximation of the global cross-structure Hessian. We then 3️⃣ compute the prunability score for each parameter as
\[
\begin{align}
\boldsymbol{P}
&=
\operatorname{diag}\!\Bigg(
\frac{1}{N_D}\sum_{i=1}^{N_D}
\big\|
\nabla_{\boldsymbol{\theta}}\,
\mathcal{L}^{\mathrm{SSL}}
\big\|^{2}
\Bigg)
\;\odot\;
\mathbf{M}\,\boldsymbol{c},
\end{align}
\]
where \( M \) is a membership matrix \( \mathbf{M}\!\in\!\{0,1\}^{N\times B} \) that expands scaling factors \( c_i \) to all parameters within the corresponding structure. Scores are then aggregated on a per-structure basis by averaging. After computing \( \boldsymbol{P}\), we 4️⃣ globally rank all structures (or parameters) to determine the pruned subset at any desired sparsity level \( S \)
\[
\Theta_S
=
\bigl\{
\theta_i \in \Theta \mid
\operatorname{rank}(P_i)
<
|\Theta|\,(1-S)
\bigr\},
\]
where \(\Theta\) is the complete parameter set and \(P_i\) denotes the score of parameter \(\theta_i\). This global ranking enables single-shot pruning, as any target sparsity \( S\!\in\![0,1] \) can be realized without retraining, Hessian storage, or additional optimization.